Category
Tech
![[SEO대응] 네이버 100 : 구글 1 vs 네이버 1 : 구글 3](https://storage.googleapis.com/nemoneai-thumbnails/a6641e59-788f-4d23-bbcf-d9666232c5db.jpg)
[SEO대응] 네이버 100 : 구글 1 vs 네이버 1 : 구글 3
— 같은 팀이 만든 두 서비스, 색인 결과가 정반대였다 두 개의 서비스를 동시에 운영하다 보면 의도치 않게 비교 실험이 된다. 같은 프레임워크, 같은 인프라, 같은 기본 SEO 셋업. 그런데 한 서비스는 네이버에서 구글보다 압도적으로 많이 색인됐고, 다른 서비스는 반대로 구글이 네이버보다 3배 가까이 많이 색인됐다. 처음엔 뭔가 기술적으로 잘못된 건가

바이브코딩으로 하는 SEO 대응 실패와 교훈
블로그 재구성을 위한 정리 문서. 두 서비스의 SEO 전략, 실제 대응 방식, 3차에 걸친 장애 대응, 그리고 시사점을 시간순으로 정리했다. 0. 배경 지금여기(now) : 2026-03-26 시작. 성수·홍대 팝업스토어/공연/축제 정보를 다루는 hyperlocal 미디어. 네이버 검색 노출이 꾸준히 잘 됨. 네모네AIM(matmatch)
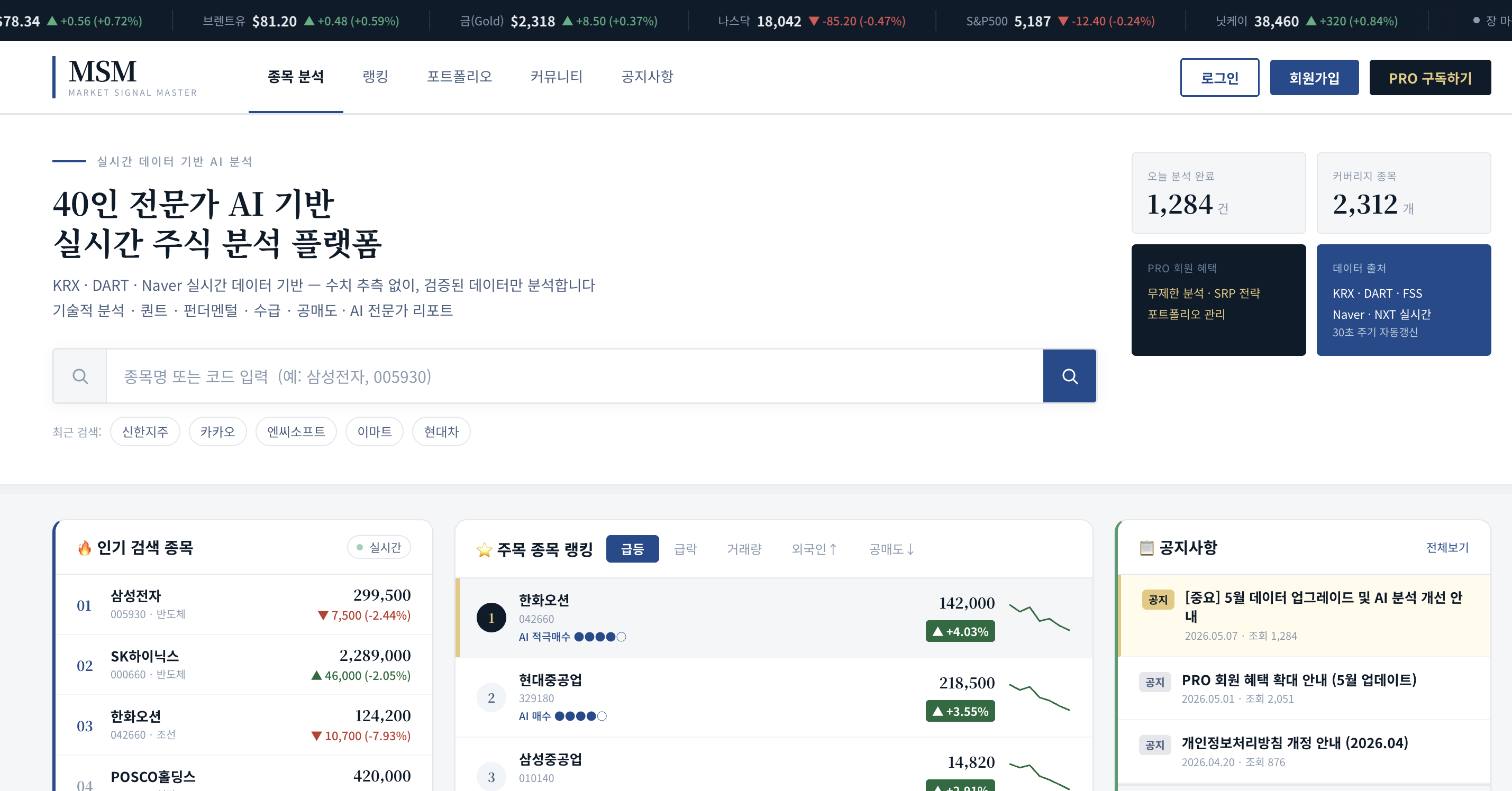
MSM(Market Signal Master) — 한국 주식 실시간 AI 분석 플랫폼을 만들면서
1. 서비스 소개: 4050 베테랑 투자자를 위한 수치 기반 AI 분석기획 의도: 기관 중심의 증권사 리포트와 실제 수치 계산 없이 문장만 생성하는 기존 포털 AI 분석의 공백을 채우기 위해 시작되었습니다.핵심 가치: 기술적 분석, 퀀트, 펀더멘털, 수급 데이터를 한곳에 모아 검증된 수치 기반으로 판단할 수 있는 환경을 제공합니다.실시간 리포트 생성: 종목

Supabse를 활용한 통합 인증(SSO) 시스템 구축에 대한 기록
현재 네모네AIM과 지금여기 2개의 서비스를 운영하면서 어쩔 수 없이 각각 2개의 회원 체계를 가지고 가고 있었는데 조만간 3번째 서비스 구축에 들어가면서 회원들의 통합 인증(SSO) 시스템 구축에 대한 니즈가 필요해졌다. 일반 회사에서는 대 작업이었겠지만 현재 서비스는 아주 가볍고 로그인이 활발한 서비스는 아니기에 빠르게 도입하는 것이 좋겠다고 생각했다.
![[Google Search Console 오류 조치] 바이브코딩의 한계라고 볼 수 있나](https://storage.googleapis.com/nemoneai-thumbnails/a0d75846-1e99-4802-9a53-3ebd8b971692.png)
[Google Search Console 오류 조치] 바이브코딩의 한계라고 볼 수 있나
구글에서 회사 홈페이지를 검색하면 제대로 정보가 표기되지 않았음. 그래서 구글 서치 콘솔(Google Search Console)에 들어가보면 색인은 성공했다는 메시지는 떴음. 아무래도 이상해서 하나하나 클릭하다보니 크롤링된 페이지>추가정보>페이지리소스를 확인하니 이런 메시지가 작게 써있었다.총 23개 중 18개 리소스를 로드하지 못함 아니, 이
구글 애널리틱스(GA4)와 자체 AnalyticsTracker 차이와 시사점
현재 네모네AIM 시스템 내부적으로 구축된 자체 애널리틱스(AnalyticsTracker)와 구글 애널리틱스(GA4)의 데이터가 차이 나는 이유를 알아보았는데 이는 측정하는 '기준'과 '원리'가 근본적으로 다르기 때문이라고. 🔍 네모네 자체 통계 측정 원리 1. 5초 체류(Delay) 규칙 (가장 큰 차이점) 원리: 사용자가 페이
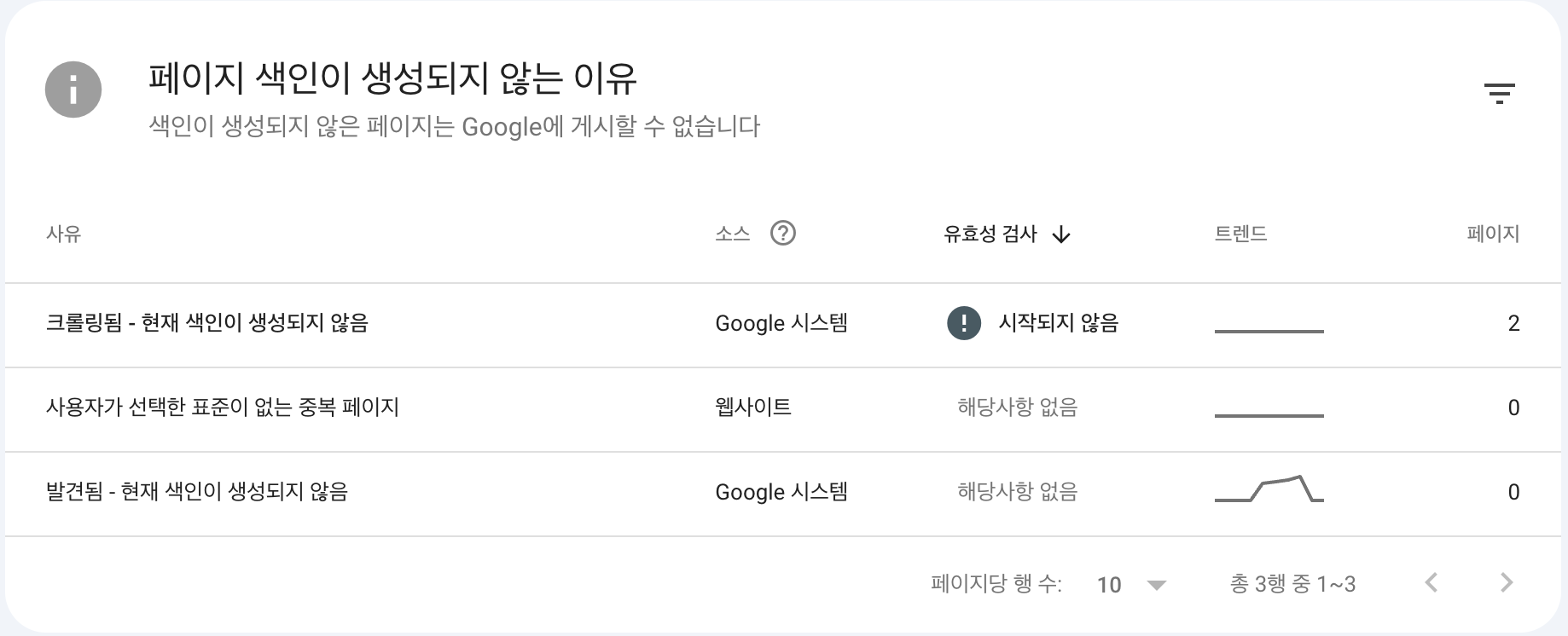
Google Search Console : 페이지 색인이 생성되지 않는 이유와 해결 정리
구글 서치 엔진 데이터를 체크하다가 현재 우리 페이지가 색인이 되고 있지 않다는 문구를 발견!(아니, 이런건 노티를 주거나 눈에 잘 뛰게 해야지. 구석에 숨겨져 있었다)구글 검색에서 색인이 잘 안 되는 핵심 원인을 명확하지 않게 그냥 '자세히 보기' 페이지 링크만 있어서 해당 내용을 차근차근 살펴보았다. 🔍 원인 분석: "모든 페이지가 자신이 메인
![🛠️ [지금여기 / NOW HERE] Full-Stack Technical Specification](https://storage.googleapis.com/nemoneai-thumbnails/36401f90-3481-445a-9a1f-d1b2954c2c5a.png)
🛠️ [지금여기 / NOW HERE] Full-Stack Technical Specification
이 프로젝트[지금여기 / NOW HERE]는 Google 에코시스템을 중심으로 하이퍼-로컬 데이터와 AI를 결합한 전형적인 Modern RAG(Retrieval-Augmented Generation) 아키텍처를 따르고 있습니다.[지금여기 / NOW HERE] 바로가기 🛠️ [지금여기 / NOW HERE] Full-Stack Technic
NEMOneAI에 대한 기술 스택 정리 (광고 제외)_ 2026. 3. 2 현재
1. Frontend * Framework: Next.js 14.2.3 (App Router) * Language: TypeScript * Styling: Tailwind CSS (Glassmorphism & Dark Theme 적용) * Icons: Lucide Reac
![[구글 애드센스 적용 실패기] 구글은 답변하기 바란다](https://storage.googleapis.com/nemoneai-thumbnails/7822caf3-6a2d-45a8-a446-4f74785acca3.png)
[구글 애드센스 적용 실패기] 구글은 답변하기 바란다
지난 2월 9일 애드센스 신청을 하고 한 달 가까이 지나고 있는 지금 여전히 그들의 승인은 나고 있지 않다. 이 실패담을 공유하고자 글을 쓴다.1차 실패 : 애드센스를 붙이고 시작하는 것이 아니였다.나는 그렇게 생각했다. 나의 소중한 컨텐츠와 데이터를 가치있게 보여줄 수 있는 방법은 무엇일까. 지금까지 수많은 창작물을 제작하고 그것을 다른 플랫폼에 게재하면